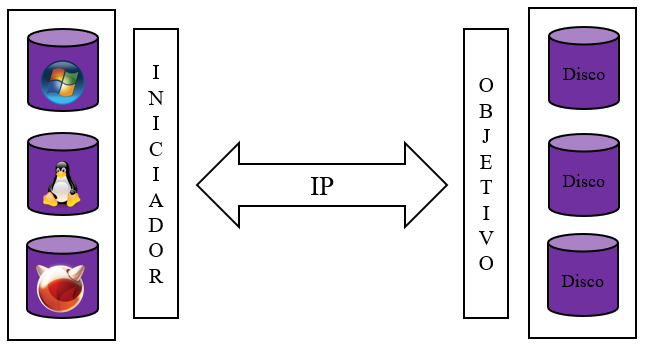
Gluster es un sistema de archivos distribuido usado para escenarios de alta disponibilidad; a diferencia de otros sistemas de archivos es escalable. Crea volúmenes que pueden estar replicados, distribuidos, dispersos o combinaciones entre ellos.
Para este tutorial usaremos un volumen replicado para evitar la perdida de información y sobre él montar algún servicio web. Estos son los servidores en los cuales trabajaremos:
192.168.100.122 nodo1.cluster nodo1
192.168.100.127 nodo2.cluster nodo2En este momento cada servidor cuenta con un disco duro de 20 GB en el dispositivo /dev/vdb. En él se creara la etiqueta, la partición con un sistema de archivos xfs para finalmente montarla en el directorio /gfs.
~]$ sudo parted /dev/vdb mklabel msdos
~]$ sudo parted /dev/vdb mkpart primary 0% 100%
~]$ sudo mkdir /gfs
~]$ sudo mkfs.xfs /dev/vdb1
~]$ sudo echo '/dev/vdb1 /gfs xfs defaults 1 2' >> /etc/fstab
~]$ sudo mount -aListo, con los comandos anteriores ya hemos montada la partición.
[root@nodo2 ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sr0 11:0 1 1024M 0 rom
vda 252:0 0 6G 0 disk
├─vda1 252:1 0 5G 0 part
│ ├─rl-root 253:0 0 4.4G 0 lvm /
│ └─rl-swap 253:1 0 616M 0 lvm [SWAP]
└─vda2 252:2 0 1G 0 part /boot
vdb 252:16 0 20G 0 disk
└─vdb1 252:17 0 20G 0 part /gfsAhora toca la instalación del paquete y habilitar el servicio.
~]$ sudo yum install centos-release-gluster9
~]$ sudo yum install glusterfs-server -y
~]$ sudo systemctl enable --now glusterdHabilitamos el servicio en el firewall.
~]$ sudo firewall-cmd --permanent --add-service=glusterfs
~]$ sudo firewall-cmd --reloadEn ambos servidores creamos el directorio que servirá para almacenar la información.
~]$ sudo mkdir -p /gfs/mirrorProbamos la conexión y listamos los elementos del cluster.
[tusysadmin@nodo1 ~]$ sudo gluster peer probe nodo2
peer probe: success
[tusysadmin@nodo1 ~]$ sudo gluster peer status
Number of Peers: 1
Hostname: nodo2.cluster
Uuid: 3431cf1d-80b8-48ac-a605-9803cb2e4cf9
State: Peer in Cluster (Connected)
[tusysadmin@nodo1 ~]$ sudo gluster pool list
UUID Hostname State
3431cf1d-80b8-48ac-a605-9803cb2e4cf9 nodo2.cluster Connected
73ae75e6-5d01-4cf5-b886-d448cd361f20 localhost Connected
En el nodo1 creamos e iniciamos el volumen.
~]$ sudo gluster volume create volume_mirror replica 2 nodo1.cluster:/gfs/mirror nodo2.cluster:/gfs/mirror
~]$ sudo gluster volume start volume_mirror
~]$ sudo gluster volume info volume_mirror
Volume Name: volume_mirror
Type: Replicate
Volume ID: 2dd69f3f-ae85-46ef-b0f3-ae3607dd06fc
Status: Started
Snapshot Count: 0
Number of Bricks: 1 x 2 = 2
Transport-type: tcp
Bricks:
Brick1: nodo1.cluster:/gfs/mirror
Brick2: nodo2.cluster:/gfs/mirror
Options Reconfigured:
performance.client-io-threads: off
nfs.disable: on
transport.address-family: inet
storage.fips-mode-rchecksum: on
cluster.granular-entry-heal: onHasta aquí, se ha creado un sistema de archivos similar a lo que se hace con NFS, la única diferencia es que está replicado en dos equipos. Ahora hay que montarlo en un cliente. El cliente será un servidor web con Apache.
[tusysadmin@www ~]$ sudo yum install httpd
[tusysadmin@www ~]$ sudo systemctl enable --now httpdEl servidor web habrá creado el directorio /var/www en el cual montaremos nuestro sistema de archivos.
~]$ sudo mount -t glusterfs nodo1.cluster:/volume_mirror /var/www/Con lo cual, ya tendremos nuestro sistema de archivos montado en el servidor.
[tusysadmin@www ~]$ sudo df -h
S.ficheros Tamaño Usados Disp Uso% Montado en
devtmpfs 484M 0 484M 0% /dev
tmpfs 496M 0 496M 0% /dev/shm
tmpfs 496M 6.9M 489M 2% /run
tmpfs 496M 0 496M 0% /sys/fs/cgroup
/dev/mapper/centos-root 5.1G 1.5G 3.4G 32% /
/dev/vda1 509M 163M 347M 32% /boot
nodo1.cluster:/volume_mirror 20G 238M 20G 2% /var/www
tmpfs 100M 0 100M 0% /run/user/0Para hacer el montado de manera automática al iniciar el servidor.
sudo echo "nodo1.cluster:/volume_mirror /var/www glusterfs defaults,_netdev 1 2" >> /etc/fstab
Al crear directorios y el archivo index.html de manera habitual en el servidor web estos son creados en los nodos. Al apagar un servidor o detener el servicio Gluster en uno de los nodos la información continua disponible en nuestro servidor web. En este caso, la única forma de perder la información del sitio sería que ambos nodos estén fuera de linea.